联邦学习

Communication-Efficient Learning of Deep Networks from Decentralized Data
基于分散数据的高效通信学习深度网络
Mcmahan H B , Moore E , Ramage D , et al. Communication-Efficient Learning of Deep Networks from Decentralized Data[J]. 2016.
摘要
- 将训练数据分布在移动设备上,通过聚集本地计算的更新来学习共享模型。我们称这种分散的方法为联邦学习。
- 提出了一种基于迭代模型平均的深度网络联合学习方法,并结合五种不同的模型结构和四个数据集进行了广泛的实证分析。
- 该方法对于数据的不平衡以及不独立同分布是具有稳定性的。
- 通信成本是主要的限制条件,与同步随机梯度下降相比,我们显示所需的通信轮数减少了 10–100 倍。
Introduction
背景
移动设备的普及带来了巨大的数据,同时数据也是天生具有隐私性的。 联邦学习,可以充分利用数量巨大的数据的同时,数据无需上传至中心,保护了隐私。 客户端利用本机的数据集,对服务器维护的全局模型进行更新。且客户端和服务器之间仅传递更新,更新操作完成后,更新数据也会删除。
本文主要贡献
- 提出联邦学习的思想;
- 设计联邦学习算法;
- 实验评估。
介绍了联邦平均算法,它将每个客户端上的局部随机梯度下降(SGD)与执行模型平均的服务器相结合。大量的实验结果表明该算法对不平衡和非 IID 数据分布具有很强的鲁棒性,并且可以将在分散数据上训练深度网络所需的通信次数减少几个数量级。
联邦学习解决的问题的特点
- 训练数据来自真实世界的移动设备,相比较以往的数据中心的代理数据,具有明显优势。
- 这些数据对隐私敏感或大小较大(与模型的大小相比),因此最好不要将其记录到数据中心,纯粹出于模型培训的目的(为集中收集原则服务)。
- 对于监督任务,数据上的标签可以从用户交互中自然推断出来。
例如图像分类模型(预测用户可能要分享的图片)以及语言文本模型(预测输入、信息回复内容等)。这些数据的特点有:
- 涉及隐私;
- 用于训练的数据的分布与传统的数据集不同;
- 标签易于获取(图片可根据用户的行为自然推断,文本是自标签的);
- 现有的模型可以解决图片、文本的处理,且都达到了 STA。
隐私问题
联邦学习所传输的数据,是很小的更新。更新是短暂的。
此外,聚合算法不需要更新的源,因此可以通过诸如 Tor 之类的混合网络或经由可信第三方来传输更新,而无需识别元数据。
联合优化
联邦优化的特点:
- Non-IID。客户提供的训练数据通常基于特定用户对移动设备的使用情况,因此任何特定用户的本地数据集都不能代表总的分布。
- Unbalanced。体现在不同的客户端产生的数据量不同。
- Massively distributed。用户数量巨大。
- Limited communication。通信受限,移动设备经常处于离线状态,或者连接速度慢或昂贵。
本文所关注的是数据的非独立同分布以及不平衡。 本文所设计的同步更新的方案:有一组固定的 K 个客户机,每个客户机都有一个固定的本地数据集。在每轮开始时,随机选择一部分客户机,服务器将当前全局算法状态发送给每一个客户机中(例如,当前模型参数)。每个选定的客户机根据全局状态及其本地数据集执行本地计算,并向服务器发送更新。然后,服务器将这些更新应用于其全局状态,并重复该过程。
优化目标:
\[\min _{w \in \mathbb{R}^{d}} f(w)\]其中,
\[f(w) \stackrel{\text { def}}{=} \frac{1}{n} \sum_{i=1}^{n} f_{i}(w)\]对于机器学习问题,一般 \(f_i(w)=\ell\left(x_{i}, y_{i} ; w\right)\) 是预测的损失函数,\((w_i,y_i)\) 是样例输入,\(w\) 是模型参数。
假设 \(K\) 个客户机划分数据集,客户机 \(k\) 的数据为 \(\mathcal{P}_{k}\)。
令 \(n_k=|\mathcal{P}_{k}|\),上述优化目标可以写为:
\[f(w) = \sum_{k=1}^{K} \frac{n_k}{n} F_{k}(w)\]其中,
\[F_k(w) = \frac{1}{n_k}\sum_{i \in {\mathcal{P}_{k}}} f_i(w)\]如果数据采样是随机的,则有 \(\mathbb{E}_{\mathcal{P}_{k}}[F_{k}(w)]=f(w)\)。但在联邦学习中,客户机数据并不是独立同分布的。
本文提出通过本地计算来减少通信成本,有两种方法:
- 增加并行量。使用更多独立的客户机。
- 增加客户机的计算量。
联邦平均算法
随机梯度下降
- 深度学习的大量成功应用几乎完全依赖于随机梯度下降(SGD)的变体进行优化;
- 事实上,许多进步可以理解为通过简单的基于梯度的方法调整模型结构(以及损失函数),使其更易于优化。因此,我们也从 SGD 开始优化联邦学习。
SGD 可以简单地应用于联邦优化问题,其中每轮通信都要进行一次单批梯度计算(比如在随机选择的客户机上)。这种方法的计算效率很高,但需要大量的训练才能产生好的模型(例如,即使使用诸如批标准化、Ioffe 和 Szegedy 等高级方法,也需要对大小为 60 的小批量进行 50000 步的 MNIST 训练)。我们在 CIFAR-10 实验中考虑了这一基线。
Baseline 算法——FederatedSGD(FedSGD)
直观方法:SGD 可以直接应用于联邦优化,即每轮在随机选择的客户端上进行一次梯度计算。 特点:计算效率高,但需要大量的迭代轮次。
算法步骤:
- 选取 clients 的 \(C\)- fraction,\(0 \leq C \leq 1\),即客户端的比例。\(C\) 则为全局的批大小,\(C=1\) 则为全批量梯度下降。
- 每个 client \(k\) 计算梯度 \(g_k=\nabla F_{k}\left(w_{t}\right)\),发送至服务器。
- 服务器计算梯度的加权平均,进行参数更新。
对于 FedSGD 来说,\(C=1\),则每个 client \(k\) 计算梯度 \(g_k=\nabla F_{k}\left(w_{t}\right)\) 后,服务器更新:
\[w_{t+1} \leftarrow w_{t}-\eta \sum_{k=1}^{K} \frac{n_{k}}{n} g_{k}\]换一种写法,对于每个客户端,对于 \(\forall k, w_{t+1}^{k} \leftarrow w_{t}-\eta g_{k}\),则服务器更新法则为 \(w_{t+1} \leftarrow \sum_{k=1}^{K} \frac{n_{k}}{n} w_{t+1}^{k}\),即客户端只更新了一次梯度。
FederatedAveraging
如果客户端在本地执行多次更新,即 \(w^{k} \leftarrow w^{k}-\eta \nabla F_{k}\left(w^{k}\right)\),这种方法就是 FederatedAveraging(or FedAvg)。即联邦平均算法。
参数:
- \(C\):每轮选取的客户机的比例;
- \(E\):每一轮,客户机的训练迭代次数;
- \(B\):客户机的每次训练的批量。
\(B=\infty\):代表 minibatch= 用户本地全部数据; \(E=1, B=\infty\):FedAvg 等价于 FedSGD。
实验任务
任务 1:MNIST 数字识别
两个模型:
- 2NN:A simple multilayer-perceptron with 2-hidden layers with 200 units each using ReLu activations (199,210 total parameters);
- CNN:A CNN with two 5x5 convolution layers (the first with 32 channels, the second with 64, each followed with 2x2 max pooling), a fully connected layer with 512 units and ReLu activation, and a final softmax output layer (1,663,370 total parameters)。
两种数据划分:
- IID:随机打乱,100 个客户端分别有 600 个样例;
- Non-IID:先排序,划分为 200 个大小为 300 的片段,100 个客户端每个分配 2 个片段。即每个只有两个数字。
任务 2:莎士比亚全集
数据划分:
- 书中每个角色用至少两行描述,构建了 1146 个 clients。
- 每个 client 有 80% 的训练行数据,20% 的测试行数据(至少一行)。
- 数据不平衡,每个角色的行数不同。
- 同时也构建了一个平衡的数据样本。
训练模型:a stacked character-level LSTM language model 输入:每一行的每个字符; 输出:预测下一个字符。
实验结果分析
提高并行
改变 \(C\),即改变每轮选取多少客户端。测试准确率 2NN 达到 97% 以及 CNN 达到 99% 时的通信轮次,以及对应的 \(C=0\) 这一基线的加速比。
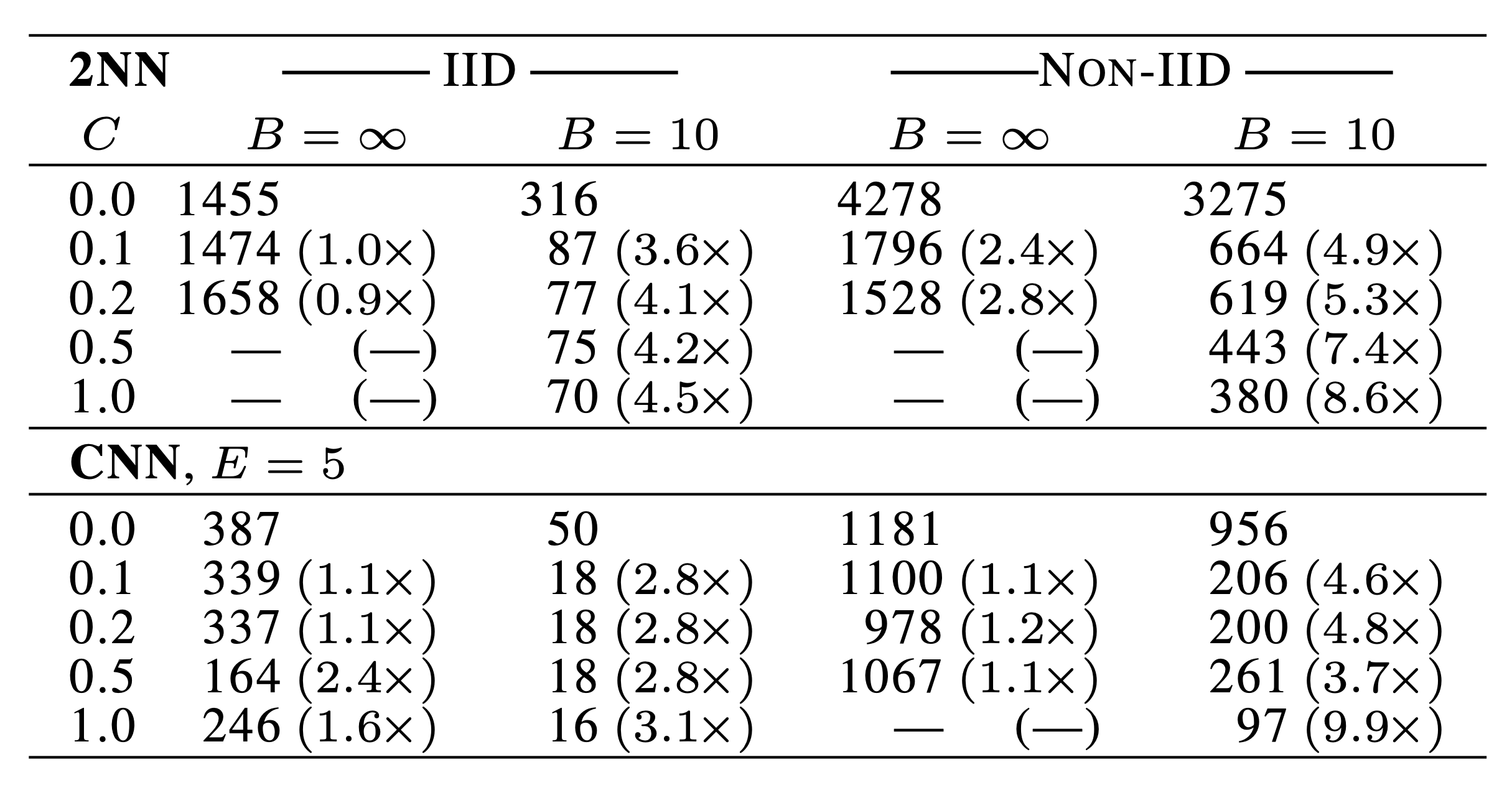 结果:
结果:
- 当 \(B=\infty\) 时,增加 \(C\) 收益很少;
- \(B=10\),效果明显,特别是非独立同分布的数据;
- \(C=0.1\) 时,计算代价低,收敛效果好。
提高客户端计算量
固定 \(C=0.1\),分析 \(B\) 和 \(E\)。
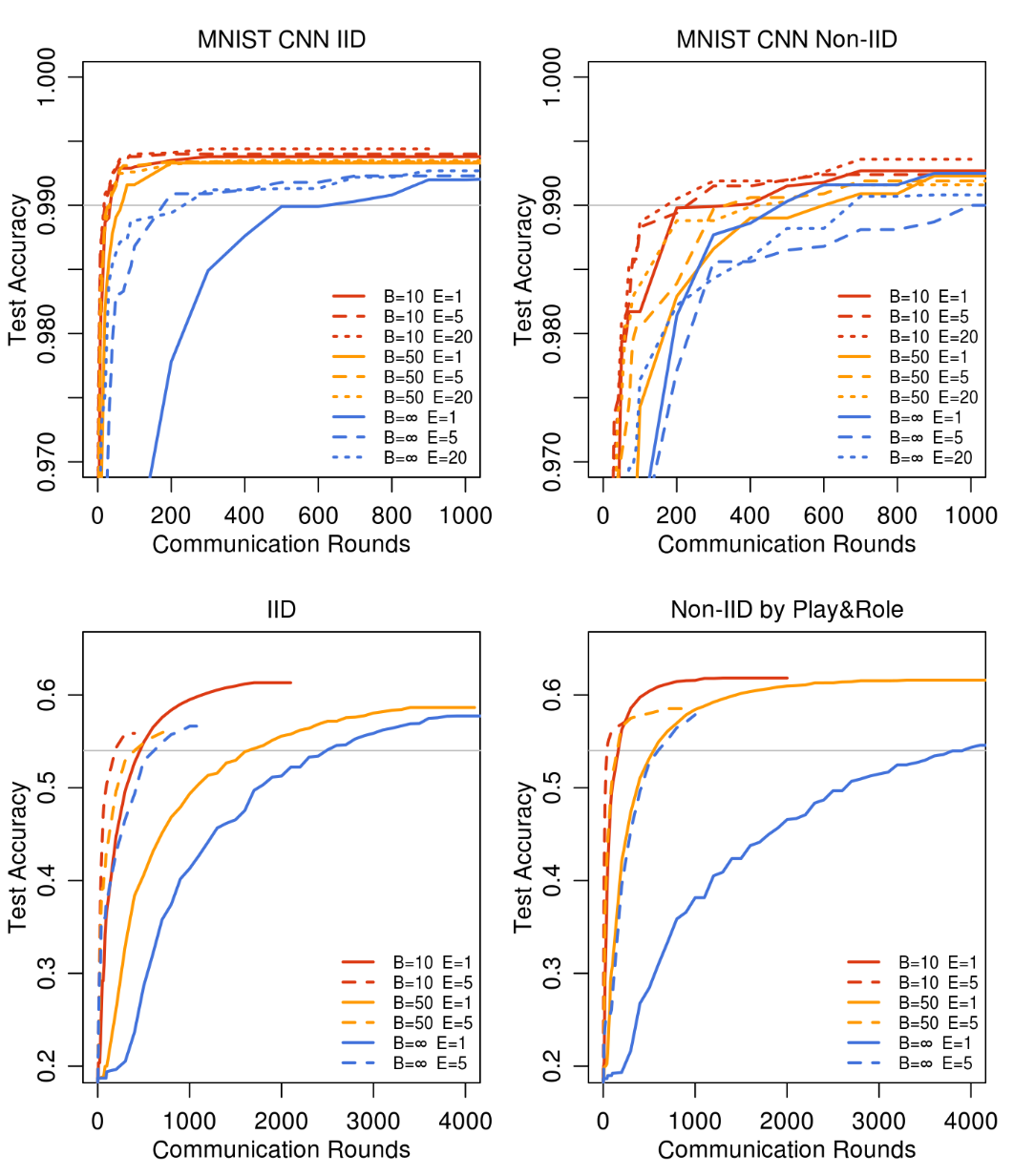
灰色为基线准确率,如下表:
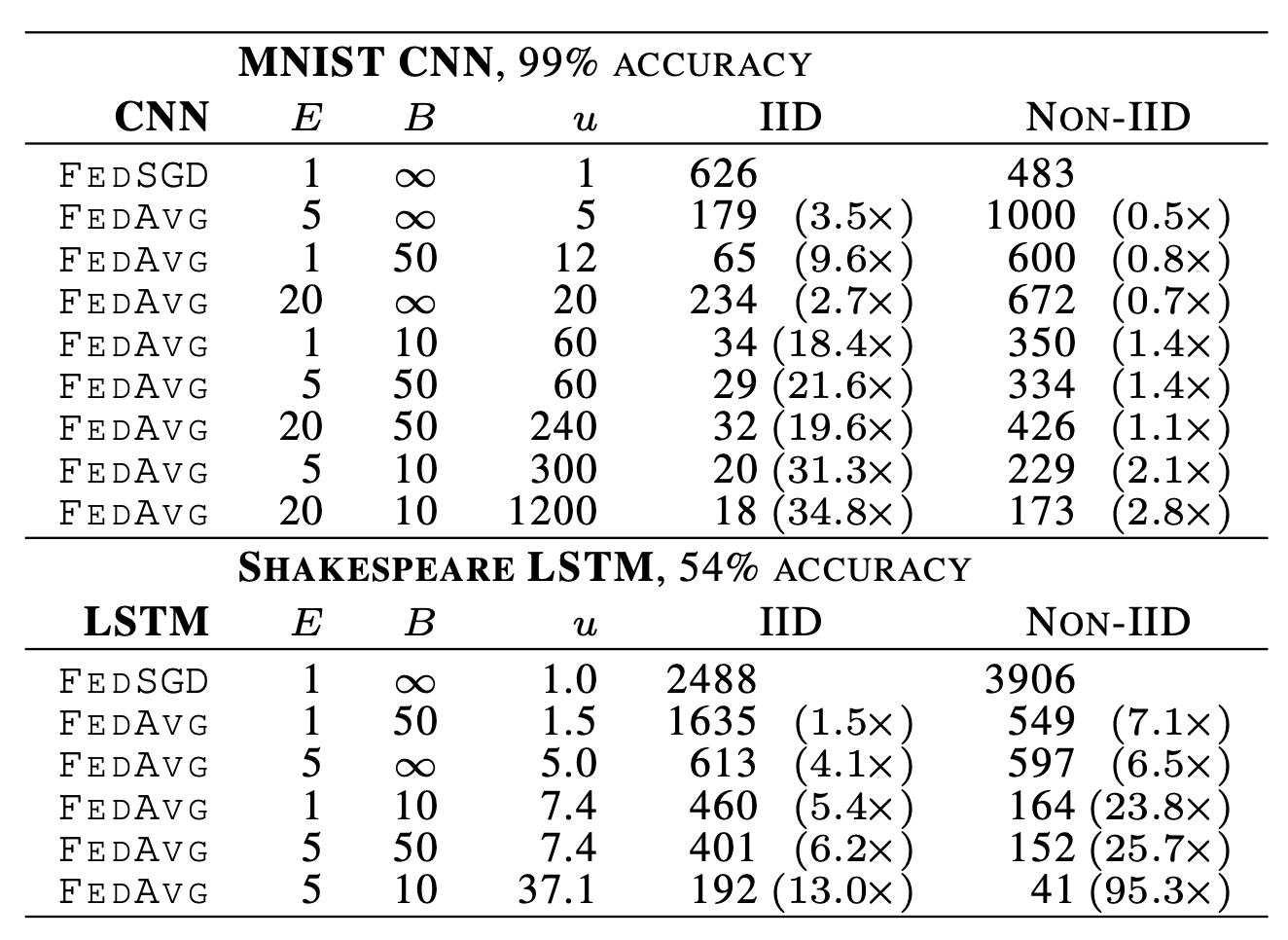
\(u=En/(KB)\),每轮预期的更新次数。
对于 IID 和 non-IID 的数据,提高 E 和 B 都能减少通信轮数,并且对于不同 pair 的手写数据集,模型平均竟然有一些效果,说明了方法具有鲁棒性。
莎士比亚的不平衡和非 IID 分布数据更能代表我们期望用于实际应用中的数据分布。在非 IID 和不平衡数据上的训练更加容易(加速 95 倍,而平衡 IID 数据则为 13 倍)。 我们推测这主要是由于某些角色具有相对较大的本地数据集,这使得增加本地训练特别有价值。
对于所有三个模型类,FedAvg 收敛到比基线 FedSGD 模型更高水平的测试集精度。即使线延伸到绘图范围之外,此趋势仍会继续。例如,对于 CNN,\(B=∞, E=1\)下FedSGD 模型在 1200 轮后最终达到 99.22% 的准确率(6000 轮后没有进一步改善),而 \(B=10, E=20\)下,FedAvg 模型在 300 轮后达到 99.44% 的准确率。我们推测,除了降低通信成本外,模型平均还产生了与 dropout 类似的正则化效益。
继续优化下去?
虽然一轮平均可能会产生一个合理的模型,但额外的几轮沟通(和平均)不会产生进一步的改进。
下图表示了 \(E\)(本地更新次数)的影响: 
对于这个模型,我们没有看到 E 的增大对收敛速度有明显的下降。
CIFAR 实验
目的:进一步验证 FedAvg。
- CIFAR-10 数据集:由具有三个 RGB 通道的 10 类 32x32 图像组成;50,000 个训练样本和 10,000 个测试样本。将数据划分为 100 个 clients,每个 client 包含 500 个训练样本和 100 个测试样本。该数据集是平衡且独立同分布的。
- 模型:包括 2 个卷积层、2 个全连接层和 1 个线性转换层生成 logit(共约 \(10^6\) 个参数)。
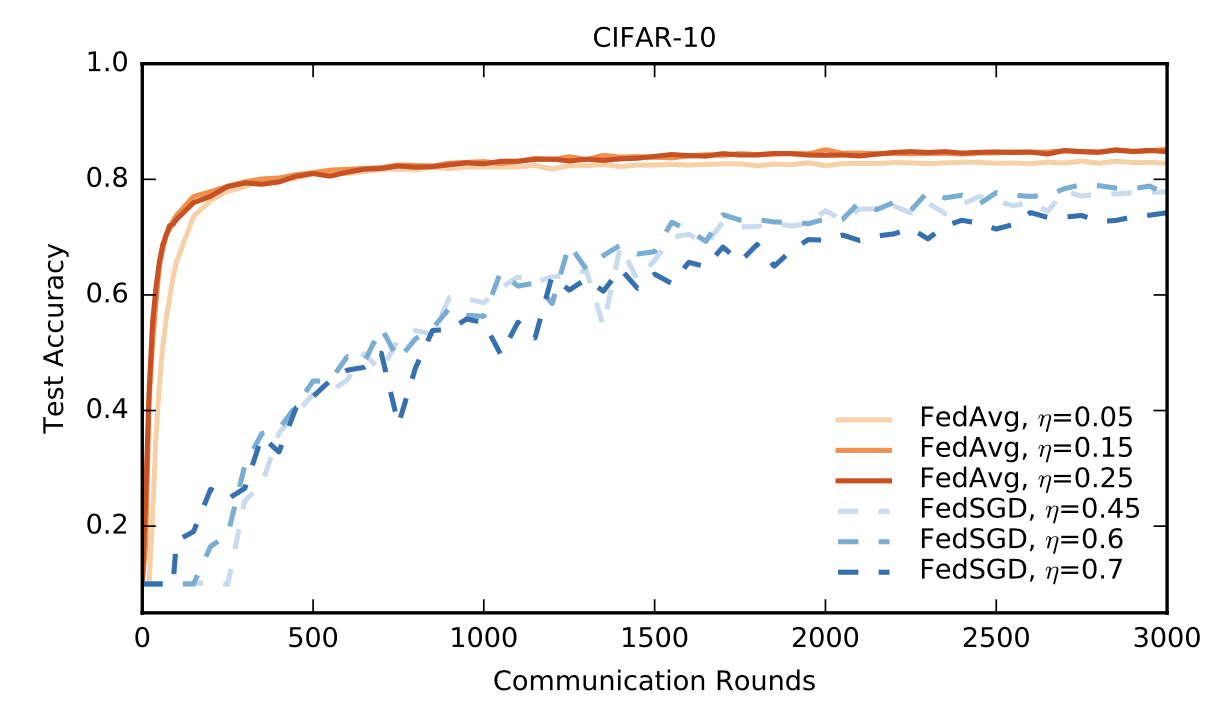
基线标准:在完整的训练集上训练,不区分用户。使用大小为 100 的小批量。在 197500 次小批量更新之后,测试准确率为 86%。
一般来说,在联邦学习中,一个批量更新都需要一次通信。而 FedAvg 仅在 2000 轮通信后就达到了 85% 的测试精度。
对于所有算法,除了初始学习速率外,我们还调整了学习速率衰减参数。下表给出了基线 SGD、FedSGD 和 FedAvg 达到三个不同精度目标的通信轮数,下图给出了 FedAvg 与 FedSGD 的学习率曲线。

大规模的 LSTM 实验
- 数据集:训练数据来自大型社交网络的 1000 万个帖子。 将帖子按作者分组,共有超过 500,000 个客户。 限制每个客户数据集为最多 5000 个字,并在来自不同作者的 \(1e5\) 个帖子的测试集上测试准确性。
- 模型:一个 256 节点的 LSTM,词汇表为 10000 个单词。每个词的输入输出嵌入维数为 192,与模型共同训练,共有 4950544 个参数。我们用了 10 个词展开。
- 训练:每轮训练 200 名客户;FedAvg 使用 \(B=8\) 和 \(E=1\)。我们探讨了 FedAvg 和基线 FedSGD 的各种学习率。下图显示了最佳学习率的单调学习曲线。

- η=18.0 的 FedSGD 需要 820 轮才能达到 10.5% 的准确率,而η=9.0 的 FedAvg 只在 35 轮通讯中达到 10.5% 的准确率。
总结与展望
在多层感知器、两个不同的卷积神经网络、两层字符 LSTM 和大规模词级 LSTM 等模型结构上的结果表明:联邦学习是可行的,因为 FedAvg 使用相对较少的通信轮来训练高质量的模型。
虽然联邦学习提供了许多实用的隐私优势,但通过差异隐私、安全多方计算或它们的组合提供更强有力的保障是未来工作的一个有趣方向。这两类技术最自然地应用于 FedAvg 之类的同步算法。
心得
本文是最早提出 Federated learning 这个概念的论文,可以说是 FL 的开山之作。联邦学习应当是未来人工智能发展的一个重要方向。目前人们对于用户隐私和数据安全的关注度是在不断提升的,这也就会导致数据孤岛,导致训练人工智能模型所需的大量的数据难以被利用。
本文首先提出的 FedSGD 是应用 FL 时梯度或模型更新速度最快的算法,它只要求每个 client 计算一次平均梯度就可以上传到 central server 进行加权平均。
但是这样通信成本还是比较高的,通信代价也是联邦学习和分布式学习的一大区别,联邦学习要尽可能降低通信成本。本文提出 FedAvg(Federated Averaging) 算法是指 local client 先在本地计算多次梯度并且更新权值,然后再上传到 server 上执行加权平均算法。这样可以降低通信次数,收敛更快。根据实验的结果,本文所提出的模型对于非 IID 数据效果还是很不错的。
本文提出的是基本的联邦学习算法,没有考虑隐私的问题,比如通过通信传输的梯度或模型可以推断出原始的数据等,这也是可以研究的方向。
感觉本文的方法还是可以用到毕设上的,但是还是要设计一个好的神经网络,比如就本文中图像识别用 CNN,语言处理的用的 RNN,都有很好的效果。